8 April 2026
Making automatic tour creation work reliably
The core idea of a tour management app is to sync the tour manager's plan with the rest of the tour party:
- the tour manager creates the plan by typing in all of the tour details into the app
- each member of the tour party is invited to download the mobile app (read-only invite). Their app syncs to the tour manager's plan
Up til now, every tour management app has handled step #1 by making tour managers go through a laborious set of forms for setting the date range of the tour, then for each day filling in every venue, hotel, and hour of the daily schedule. For a big tour, this takes a long time. Here are the forms you need to fill out in the current industry leading app to initialise just the venues in a new 3-week tour:
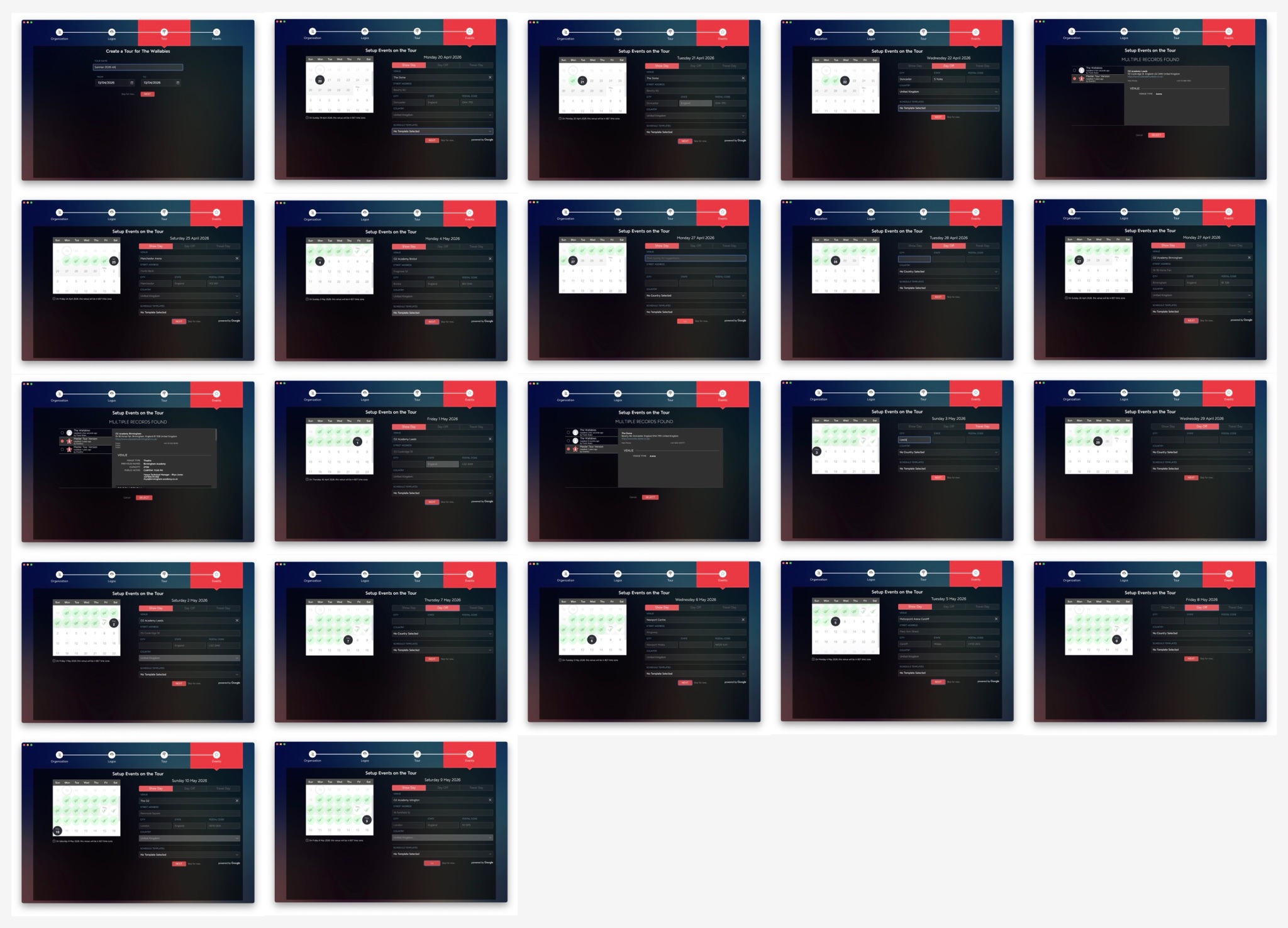
Tourflow bypasses typing in tour plans at all: instead, tour managers do a handful of copy-pastes of information they already have in their emails + notes. All in all this saves several hours of data entry for each week they are advancing a tour.
For example, to create a tour, they skip all the forms above and go to the date list they were emailed when they were hired and copy-paste the entire email into Tourflow. No matter the format, Tourflow parses the schedule and converts it into a real tour (including matching all venues to real addresses). Typing is bypassed entirely.
There's an equivalent process for adding travel and accommodation to each day: tour managers just drag and drop booking confirmation PDFs into that day - or just copy paste the entire confirmation email.
In all of these cases, we're turning messy text into structured data. Obviously it's easy to imagine implementing this with LLM calls with structuredOutputs: true, but as the saying goes: getting to the first demo is easy, making it work in production is hard.
Edge cases
By way of illustration - when you demo the above to any savvy tour manager they will immediately have questions:
- will it work on my 100-date world tour?
- will it work with this inconsistently formatted schedule from a disorganised band manager?
- what about when the venue name is misspelled?
- what happens with festivals? Festivals aren't linked to real world addresses.
There are 10s of questions like this - all variants of "does it work well across all edge cases?", each revealing a new dimension of the input data possibility space.
An engineer would have others:
- how does LLM non-determinism affect results? e.g. what's the failure rate for the same input schedule, across multiple repeats?
- how does accuracy vary as you scale the tour length?
- how fast is it? What's the SD? How does that vary with tour length?
- what about when you
cmd + cthe entire gmail webpage, capturing all framing and text outside the email body as well?
Tour managers are especially sensitive to inaccuracies: mid-size tours often operate on razor-thin margins and if something is added on the wrong date and not double-checked it can take 30% off the bottom line of the entire tour. Of course, it's not good enough to force them to double-check everything - in fact we are aiming for the opposite: to be at the point where it is dangerous to not use our auto-parsing, because the human error rate is so much higher than our automatic path.
To get there, we need to make sure parsing works across the entire distribution of possible inputs, and despite the nondeterminism of the underlying LLM. Because of this, it's very difficult from just an initial implementation to see whether the labelling pipeline works well enough: you'll get accurate results for some inputs but not others, exceptions, many of which won't reliably reproduce, and most importantly - simply imagining a handful of example tour schedules means you're only probing performance at a few arbitrary points within a vast input possibility space. To remedy this Tourflow has a two-pronged approach - pessimistic logging and evals.
Evals
Tourflow's evals are a comprehensive set of pasted input text blobs, each with corresponding JSON for the expected correctly parsed labels, chosen to span the entire input possibility space rather than just probe points in the centre. One simple example: when parsing tour schedules, to ensure we've covered the "number of dates" dimension, our "add tour" eval set contains one input schedule with just 3 tour dates, another with over 50, and several others in between. Our input data is chosen to cover the combinations of all the dimensions - that is to say, one of the "worst" examples contains the extremes of all of number of dates, inconsistency of formatting, amount of unrelated preamble text, misspellings, and several other dimensions. It's not as simple as just providing a single "worst" example though: not all dimensions have a clear good<>bad alignment - many are neutral and just bring a new mode of variance - so there can in fact be many ways of being the "worst" example. But you get the idea: proper combinatorial datasets cover all combinations regardless.
Our evals run all at once, passing all inputs to the labelling pipeline, scoring the outputs against the expected results, and combining results from the runs into a single set of scores, which we render in a report that plots scores over time as we improve the pipeline.
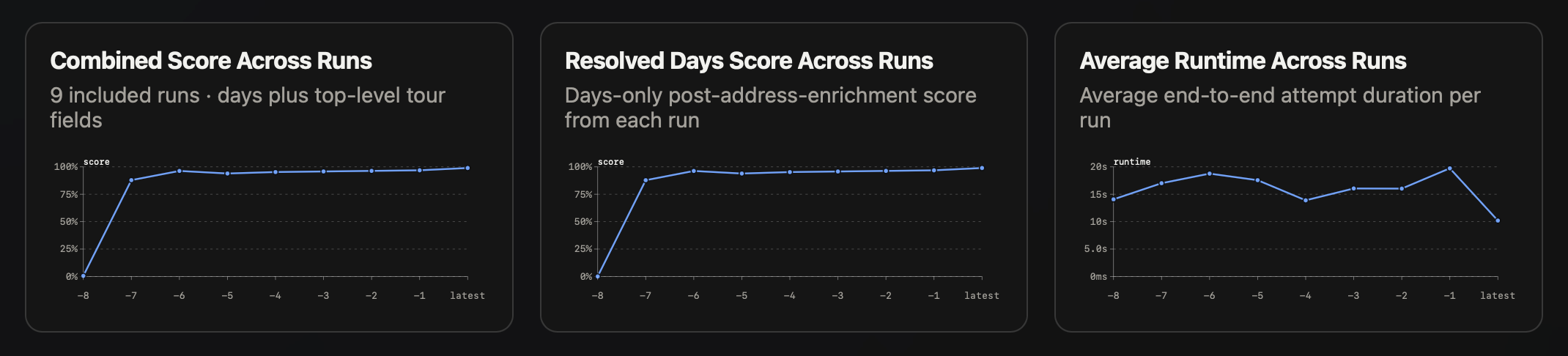
Our reporting goes all the way down to line-by-line diffs between LLM results and expected results for each field. Now whenever we modify the pipeline, we run the evals and get visibility of labelling performance across the entire range of possible input data.
This tooling lays out the failure modes of our software very clearly, essentially presenting a clear list of bugs that we've been able to work through. We've done that now, to the point we're confident labelling works reliably for small-to-medium UK/Europe tours (the types of tours our initial users manage).
Pessimistic logging
So far we've talked about ensuring we are prepared for the entire range of input data that we can imagine. What happens when we get something completely out-of-distribution, that we haven't imagined yet? We accept that this will happen - even after talking to lots of tour managers and seeing a wide range of real-world schedule emails - and when that happens we may end up with failed labelling. We want to be able to recover from these events as fast as possible: understand the error quickly, without having to battle non-deterministic LLMs to try to reproduce it, then update evals and the pipeline.
One thing that stands in the way of this is the cause of a single exception can be difficult to track down. Right now, instead of a single LLM call, our labelling pipeline is a chain of calls. It looks like this:
Each solid bordered node here is a LLM call: we do an initial segmentation of the pasted text to extract single-date substrings, followed by extraction of tour details from each segmented day. That's a lot of places something can go wrong - so to clear this up we persist exhaustive logs of each stage of the pipeline as it progresses:
For every stage and LLM call, these logs are appended to a family of records in the DB, storing:
- initial input text
- complete prompt
- full LLM response, including HTTP metadata
- any exception caught within the app
- timings of each stage of the labelling pipeline
These logs are initialised before the pipeline starts and incrementally updated at each stage, so this is all persisted even if the user doesn't create a tour from the preview of the parsed result. In this way, for almost any failure condition at any stage in the parsing pipeline we capture as much diagnostic information as possible without having to battle to reproduce it. From here it's trivial to see which LLM call failed, replay calls exactly, and even analyse pipeline performance for each run:
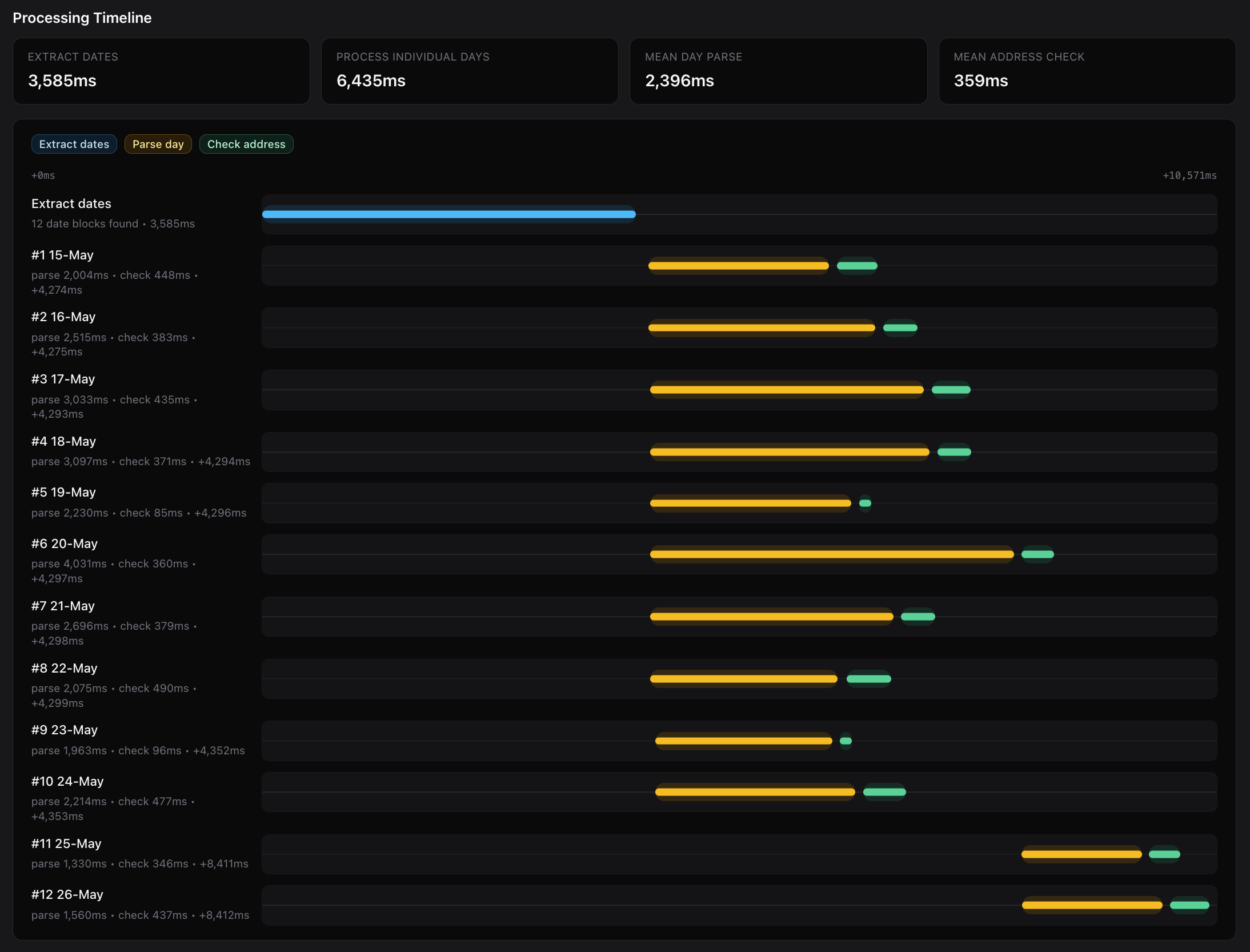
With this tooling, we're now pretty confident that we'll be able to do the "march of 9s" in a low-overhead way, and eventually get to the point where tour managers' experience is that auto labelling is safer than manual entry.
That's it - thanks for reading.